问题描述
我有一个PDF文件,这是扫描一本书的结果。
在此文件中,本书的2页对应于PDF中的1。所以当我在PDF文件中看到一个页面时,我实际上看到了这本书的2页。

(original)
我想知道是否有任何方法可以将此文件转换为另一个PDF,其中该书的1页对应于PDF的1页,即正常情况。
最佳解决办法
尝试使用Gscan2pdf,您可以从软件中心下载,也可以从命令行sudo apt-get install gscan2pdf安装。
打开Gscan2Pdf:
-
档案>导入您的PDF文件;现在你有一个页面(见左栏):
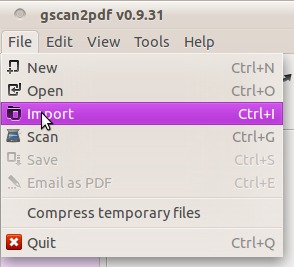

-
那么工具>清理;
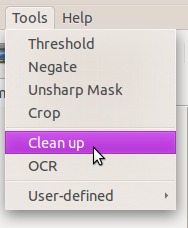
-
选择double作为布局,将#output页面选为2,然后单击OK;
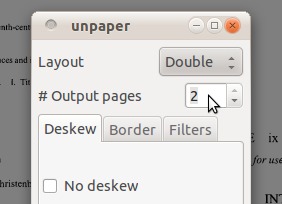
-
Gscan2pdf拆分您的文档(除此之外,它还会清理它并对其进行校正等)现在您有两个页面:

-
如果您对结果满意,请保存PDF文件。





次佳解决办法
您可以使用mutool,一个MuPDF 命令行工具(sudo apt-get install mupdf-tools):
mutool poster -x 2 input.pdf output.pdf
如果要执行垂直拆分,也可以使用-y。
第三种解决办法
我会用Briss。它允许您选择每个页面的各个区域,每个区域都可以转换为新页面。

第四种办法
另一种选择是ScanTailor。该程序特别适合一次处理多个扫描。
apt-get install scantailor
遗憾的是,它仅适用于图像文件输入,但它足以将扫描的PDF转换为jpg。这是我用来将整个PDF目录转换为jpgs的one-liner。如果PDF有n页,则会生成n个jpg文件。
for f in ./*.pdf; do gs -q -dSAFER -dBATCH -dNOPAUSE -r300 -dGraphicsAlphaBits=4 -dTextAlphaBits=4 -sDEVICE=png16m "-sOutputFile=$f%02d.png" "$f" -c quit; done;
我已准备好分享截图,但我没有足够的代表发布它们。
ScanTailor输出到tif,因此如果您希望文件以PDF格式返回,您可以使用它为每个页面制作PDF。
for f in ./*.tif; do tiff2pdf "$f" -o "$f".pdf -p letter -F; done;
然后,您可以使用此one-liner或PDFShuffler等应用程序将任何或所有文件合并为一个PDF。
gs -q -sPAPERSIZE=letter -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -sOutputFile=output.pdf *.pdf