
什么是grep?
今天将要使用的grep实用程序是Unix工具,与egrep和fgrep实用程序属于同一家族。这些都是Unix工具,旨在对文件和文本执行重复搜索任务。您可以通过grep命令指定特定的搜索条件来搜索文件及其内容,以获取有用的信息。
因此,他们说GREP代表“全球正则表达式打印”,但是“ grep”命令是从哪里来的呢? grep基本上来自特定命令,该命令用于名为ed的非常简单而古老的Unix文本编辑器。 ed命令的运行方式如下:
g /re /p
该命令的目的与通过grep搜索的含义非常相似。此命令获取与特定文本模式匹配的文件中的所有行。
让我们进一步探索grep命令。在本文中,我们将解释grep实用程序的安装,并提供一些示例,您可以通过这些示例确切了解如何以及在哪种情况下使用它。
我们已经在Ubuntu 18.04 LTS系统上运行了本文中提到的命令和过程。
安装grep
尽管大多数Linux系统默认使用grep实用程序,但是如果您的系统上未安装grep实用程序,请执行以下步骤:
通过Dash或Ctrl + Alt + T快捷方式打开Ubuntu终端。然后以root用户身份输入以下命令,以便通过apt-get安装grep:
$ sudo apt-get install grep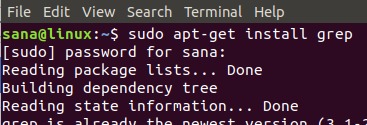
在安装过程中提示您输入y /n选项时,输入y。之后,将在您的系统上安装grep实用程序。
您可以通过以下命令检查grep版本来验证安装:
$ grep --version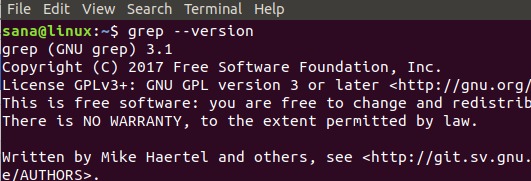
使用grep命令和示例
通过提供一些可以使用它的方案,可以最好地解释grep命令。这里有一些例子:
搜索文件
如果要搜索包含特定关键字的文件名,则可以通过grep命令过滤文件列表,如下所示:
句法:
$ ls -l | grep -i“搜索词”
例子:
$ ls -l | grep -i sample该命令将列出当前目录中的所有文件,并以包含单词“private”的文件名列出。

在文件中搜索字符串
您可以通过grep命令从包含特定文本字符串的文件中获取句子。
句法:
grep “string”文件名
例:
$ grep “sample file” sampleFile.txt
我的样本文件sampleFile.txt包含具有字符串“sample file”的句子,您可以在上面的输出中看到。关键字和字符串在搜索结果中以彩色形式显示。
在多个文件中搜索字符串
如果要从同一类型的所有文件中搜索包含文本字符串的句子,则可以使用grep命令。
语法1:
$ grep “string” filenameKeyword *
语法2:
$ grep “string” *。扩展名
范例1:
$ grep "sample file” sample*
此命令将从文件名包含关键字“sample”的所有文件中获取所有包含字符串“sample file”的句子。
范例2:
$ grep "sample file” *.txt
该命令将从所有扩展名为.txt的文件中提取所有包含字符串“sample file”的句子。
在不考虑字符串大小写的情况下在文件中搜索字符串
在上述示例中,幸运的是,我的文本字符串与示例文本文件中的文本字符串相同。如果输入以下命令,则搜索结果将为零,因为文件中的文本不是以upper-case单词“Sample”开头
$ grep "Sample file" *.txt
让我们告诉grep忽略搜索字符串的大小写,并通过-i选项基于该字符串打印搜索结果。
句法:
$ grep -i “string”文件名
例:
$ grep -i "Sample file" *.txt
该命令将从所有扩展名为.txt的文件中提取所有包含字符串“sample file”的句子。这将不考虑搜索字符串是大写还是小写。
根据正则表达式进行搜索
通过grep命令,您可以指定带有start和end关键字的正则表达式。输出将是包含您指定的开始和结束关键字之间的整个表达式的句子。此功能非常强大,因为您无需在搜索命令中编写整个表达式。
句法:
$ grep “startingKeyword.*endingKeyword”文件名
例:
$ grep "starting.*.ending" sampleFile.txt
该命令将从我在grep命令中指定的文件中打印包含表达式的句子(从我的startingKeyword到我的endingKeyword结束)。
在搜索字符串之后/之前显示指定的行数
您可以使用grep命令在文件的搜索字符串之前/之后打印N行。搜索结果还包括包含搜索字符串的文本行。
关键字字符串后N行的语法:
$ grep -A “string”文件名
例:
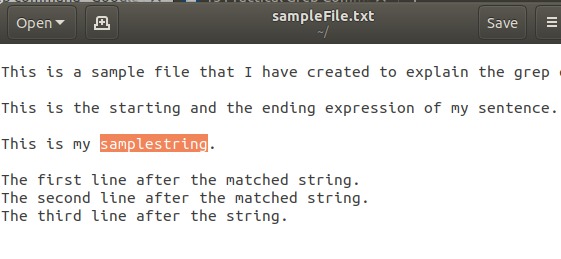
$ grep -A 3 -i "samplestring" sampleFile.txt这是我的示例文本文件的样子:
这是命令输出的样子:
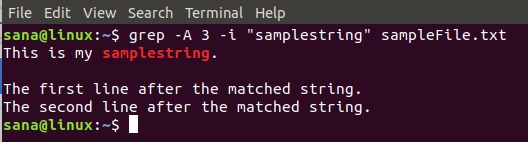
它显示了我在grep命令中指定的文件中的3行,其中包括包含搜索到的字符串的一行。
关键字字符串前N行的语法:
$ grep -B “string”文件名
您还可以在文本字符串“周围”搜索N行。这意味着文本字符串前N行,后N行。
关键字字符串周围N行的语法:
$ grep -C “string”文件名
通过本文介绍的简单示例,您可以掌握grep命令。然后,您可以使用它来搜索可能包含文件或文件内容的过滤结果。这样可以节省在精通grep命令之前浏览整个搜索结果所浪费的大量时间。